Additional Tables Flattening And Transliteration
Introduction
The streaming data can be used to derive multiple functionalities performed on the Reltio-based MDM System.
![]()
Reading Additional Tables
The additional tables which were populated with streaming data have the same structure as the EVENT_RTI.
table. It contains a column called event_payload, which is a json of the reltio event data. Filter the table data by object_name like 'configuration/entityTypes/' and you can get entity data. The OBJECT_ID has the entity_uri.
Flatten the JSON and get the required columns from it to populate the transliteration table.
Sample Transliteration Flattened Table Example
Table Name: Transliterate_Names
|
Column Name |
Data type |
Description |
|---|---|---|
|
Event_id |
varchar |
Id from event_rti table |
|
Entity_Uri |
varchar |
Uri of the entity being transliterated |
|
Created By |
varchar |
User id |
|
firstName |
varchar |
source transliterated firstName |
|
lasName |
varchar |
source transliterated lastName |
|
firstNameX |
varchar |
target transliterated firstName |
|
lastNameX |
varchar |
target transliterated lastName |
|
data_source |
varchar |
source providing the entity data, example. configuration/sources/OK |
|
crosswalk_value |
varchar |
crosswalk value used to identify the entity for update |
|
source_table |
varchar |
source table to be used for crosswalk |
Sample Query to Populated Flatten Table
insert into Transliterate_Names (enitity_uri,createdBy,firstName,lastName)
select object_id as uri,
parse_json(EVENT_PAYLOAD):object:createdBy::String as createdBy,
parse_json(EVENT_PAYLOAD):object:attributes:firstName[0]:value::String as firstName,
parse_json(EVENT_PAYLOAD):object:attributes:lastName[0]:value::String as lastName,
parse_json(EVENT_PAYLOAD):object:attributes:Country[0]:value::String as Country
from ODP_CORE_STREAM.MDM_RELTIO_DEV2_V3_EVENT_RTI
where object_name like 'configuration/entityTypes%'
After the transliteration tables have been populated, a pipeline can be created to transliterate and populate the target columns The below section explains the creation and configuration of this pipeline.
Create/Configure Transliteration Pipeline
Prerequisites
-
Access to ODP s3 bucket
-
Permission to run a data pipeline
To Create/Configure Transliteration Pipeline
-
Go to the data pipeline URL: <application url>/datapipeline/task-group.
Example: https://iqviadev-dev-sandbox.dev-usv.iqodp.io/datapipeline/task-group
-
Create a new task group or use an existing task group. Click Task Group.
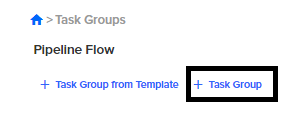
-
Click Add Task to add a new task.
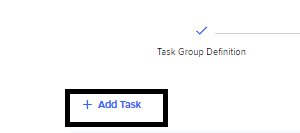
-
Choose the Python Executor plugin type.
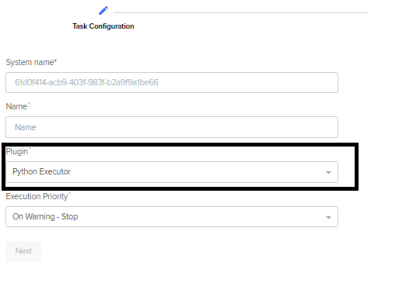
-
Copy the script folder from the S3 ODP bucket to your S3 location. The script folder should be in s3://<odp bucket>/Tools/transliteration_python_script
Example: s3://oa-dev-sandbox-env-iqviadev-odp/Tools/transliteration_python_script
Alternatively the script folder can be downloaded from Gitlab
https://gitlab.ims.io/End2EndPlatfrom/idp/data-mgmt-scripts/-/tree/dev/Scripts/Tools/transliteration_python_script.
-
Go to the Python task created from step 3.
Click Add Step to add a new step.
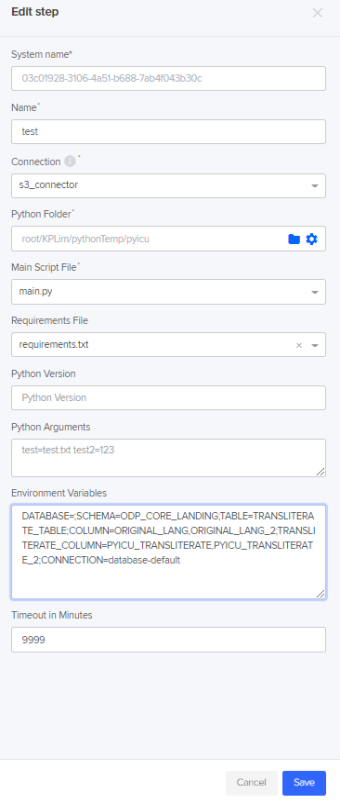
Name
Description
Name
Name of step.
Connection
Name of s3 connection that has access to the script you copied.
Python Folder
Folder path of script folder. Example.
root/Folder 1/transliteration_python_script
Main Script File
Should be main.py.
Requirements File
Should be requirements.txt
Timeout in Minutes
Increase this if you are transliterating a large number of rows(above 10,000+).
Environment Variables
Environment variables control how the transliteration script is run. They are key value pairs using = and are separated by ;.
Example: DATABASE=;SCHEMA=ODP_CORE_LANDING;TABLE=TEST_TABLE;COLUMN=ORIGINAL_LANG,ORIGINAL_LANG_2;TRANSLITERATE_COLUMN=PYICU_TRANSLITERATE,PYICU_TRANSLITERATE_2;CONNECTION=database-default
|
Name |
Required |
Description |
|---|---|---|
|
DATABASE |
N |
Name of database to use. By default it can use the default database specified in the connection. |
|
SCHEMA |
Y |
The name of the schema your table is in. |
|
TABLE |
Y |
The name of your table |
|
COLUMN |
Y |
Name of column to transliterate. These can be a comma separated value. Example: ORIGINAL_LANG,ORIGINAL_LANG_2 |
|
TRANSLITERATE_COLUMN |
Y |
Name of column to create for transliteration. These can be comma separate values. Example: RESULT_COLUMN_1,RESULT_COLUMN_2 |
|
CONNECTION |
N |
Name of database connection to use. By default this is database-default. |
|
BATCH_SIZE |
N |
Number of rows to pull from snowflake. By default this is 500. Lower this if you run into memory issues. |
|
THREAD_POOL_SIZE |
N |
Number of threads to use. Default is 15. Lower if you run into memory issues. Increase for faster performance. |
Run the Task Group.

If you select from the table, after the task group is run, the columns defined in TRANSLITERATE_COLUMN should be present with the transliterated value in Latin script(English alphabet).
